Unity Compute Shader
3D 虛擬影像即時互動 期末報告
相信大家在遊戲中都有看過一些很複雜炫泡的特效,一定會很好奇為什麼這樣做不會 Lag,像是各種複雜的粒子效果、大量物體同時移動、物理模擬等等。

這些酷酷特效的背後到底做了哪些工作呢?這篇文章將來探討如何在 Unity 使用 Compute Shader 加速計算,還會提及一些比較常見的優化遊戲效能的技術。
本文有點長,而且內容有點 Hardcore,涉及到 CPU 和 GPU 的協作、Shader 的應用、HLSL 等等,可能需要一些圖學的背景知識會比較好理解,算是比較進階的教學。
CPU、GPU 基本介紹
大家都知道,GPU (顯示卡) 是用來處理各種圖形渲染的工作,想要暢玩 3A 大作必定要先升級你的顯卡。那麼 GPU 為什麼有能力處理遊戲渲染呢?只用 CPU 不行嗎?
事實上是可以的 XD,只是非常非常慢,下面這個影片就沒有用 GPU,單純用最猛的 CPU 去跑 GTA-5,結果是跑得動的,但是 FPS 低到不行,根本玩不下去
至於為什麼會這樣,就要先了解兩者的工作差異,這邊就拿最近最紅的 NVDIA Demo 的範例來介紹

CPU 就像是一個天才,什麼都會、什麼都能做,能夠精確地完成任務,但是只能一項一項做。
在你的電腦中,CPU 扮演著大腦的角色,負責處理各種複雜的工作,處理作業系統和應用程式的所有運算任務,像是不斷切換正在執行的程式,讓它們看起來好像在同時執行一樣,或是處理你滑鼠點擊、鍵盤輸入等等,最底層的硬體都是由 CPU 負責的。

而 GPU 就像是一堆普通人,每個人只會做相同類型的普通計算,人與人之間的工作沒有關聯,不會影響彼此。這些人沒辦法做複雜的工作,但是它們可以同時工作,完成大量計算的任務。
在圖形渲染中,以最簡單的例子來講,我們會需要去處理每個 Vertex 的 Transformation,把模型的每個 vertex 投影到螢幕上 (每個 vertex 要乘上相同的變換矩陣)。我們還要處理每個 Pixel 的 Lighting (每個 Pixel 要乘上相同的光照計算公式)…
可以看到,每個 vertex、pixel 都要做相同的工作 (乘上相同的某某東西),這時候就可以利用 GPU 強大的平行計算能力,快速處理這些龐大且相同的工作。
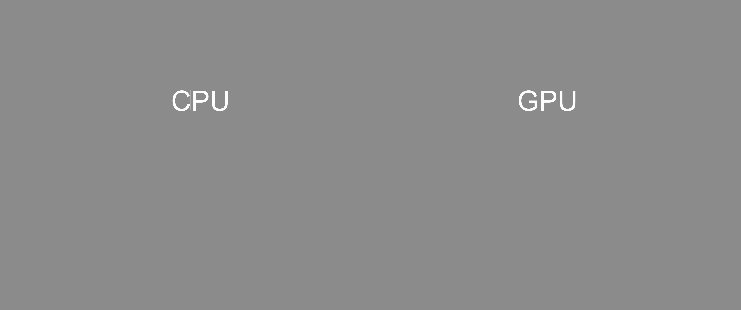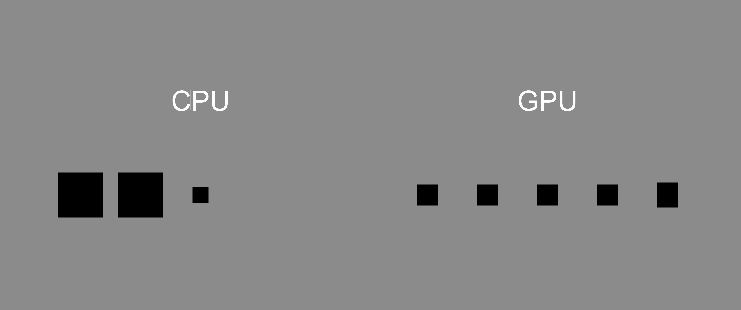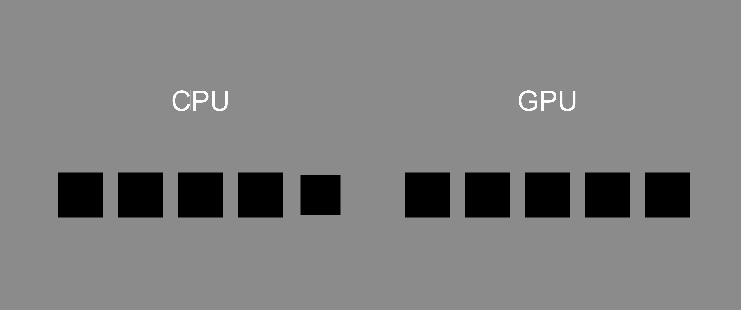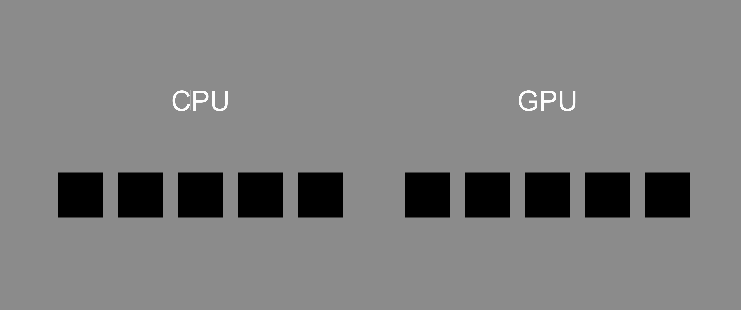
事實上,現代 CPU 通常都有 4 核、8 核等等,也擁有平行計算的能力,但是跟 GPU 的上百、上千核來比還是相形見絀,當然這邊不是說 CPU 就比不上 GPU,只是說兩者擅長的工作不同。
GPGPU (General-Purpose GPU computing)
最近幾年 NVDIA 的市值蒸蒸日上,全因為 NVDIA 在十幾年前下的一步棋,也就是推出 CUDA (NVDIA 對 GPGPU 的正式名稱)。當時 NVDIA 投入了大量的資金成本在研發 CUDA,外界卻是質疑一片,完全沒人看好這個操作,誰知道在 2024 年的現在,這成為自駕車發展、加密貨幣挖礦、AI 時代的關鍵。
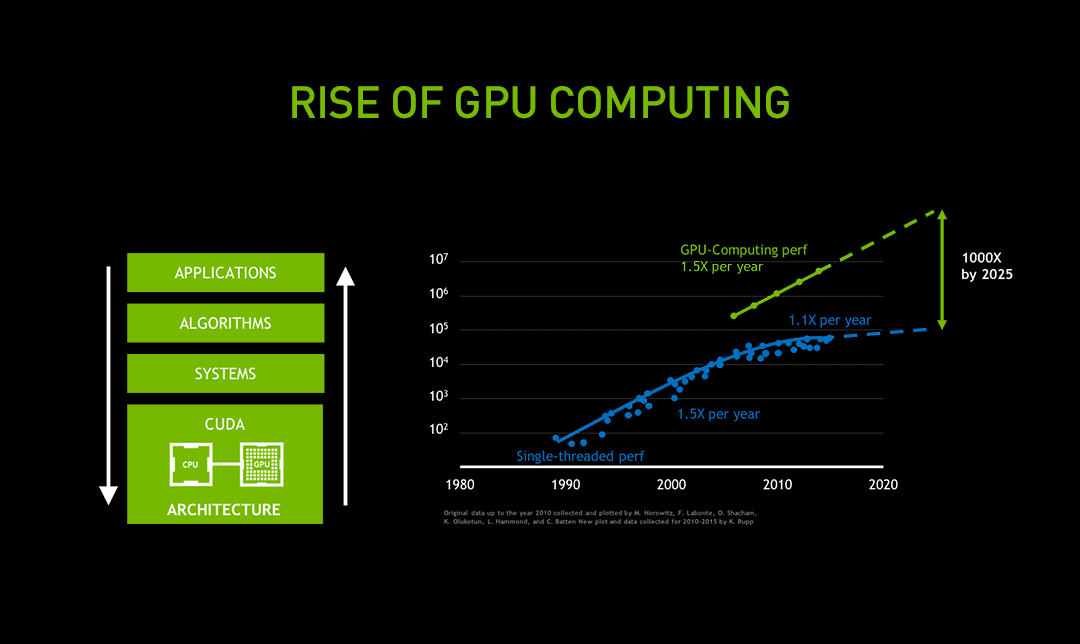
那麼 GPGPU 到底是什麼?簡單來說,在早期 GPU 主要用於圖形處理,用於加速電腦圖形渲染。後來人們開始意識到 GPU 具有強大的平行運算潛力,不應該僅僅局限於圖形處理。黃仁勳看準這點,於是 NVIDIA 於 2006 年推出了 CUDA 平台,開啟了 GPU 通用計算的大門。CUDA 允許開發者使用類 C 語言(CUDA C/C++)編寫程式來利用 GPU 的平行運算能力,加速各種類型的應用程式。
以前 GPU 都只拿來做圖形處理,要算數學都只能靠 CPU。現在,我們能夠把大量的數學丟給 GPU 做,利用他強大的平行計算能力快速出結果,不再侷限於圖形處理,這也是為什麼它叫做 GPGPU (圖形處理器通用計算)。
介紹了那麼多背景知識,終於可以進入 Unity 的部分了
Compute Shader
現在你已經了解 GPGPU 是什麼東西,而 Compute Shader 就是在 Unity 中實現 GPGPU 技術之一,我們可以自己寫一些程式到 GPU 上面跑,也就是前面說的,我們能夠把大量的數學丟給 GPU 做,利用他強大的平行計算能力快速出結果,在 Unity 中我們就可以利用 Compute Shader,減少 CPU 的 loading,增加遊戲的效能。
想像一下現在有個場景長這樣

場景共有 1000000 個粒子,如果把這些全部都塞在 Update() (CPU 端) 裡面去算會是多可怕的事情,因此我們勢必要直接丟給 GPU 去計算並直接渲染出來,這時候就可以用 Compute Shader 來達成這件事情,CPU 做的事情就只有準備 Data (記憶體要給多少之類的) 以及啟動 Compute Shader。
建立 Compute Shader
在 Unity 新增 Compute Shader,點擊右鍵就可以直接新增 .compute 檔案
這邊順便新增等等會用到的檔案
執行 Compute Shader
Shader 端
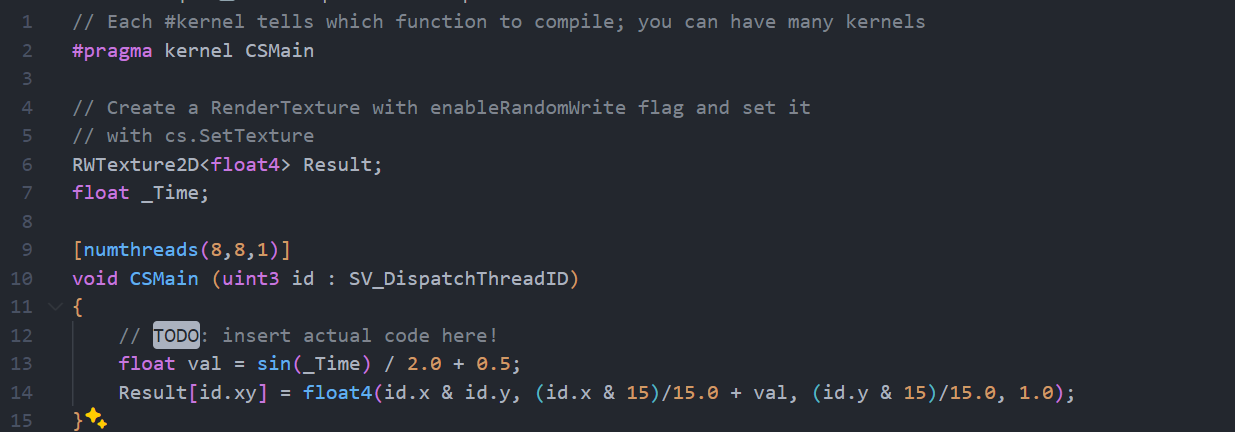
Unity 的 Compute Shader 的語言是 HLSL,打開檔案可以看到下面的內容
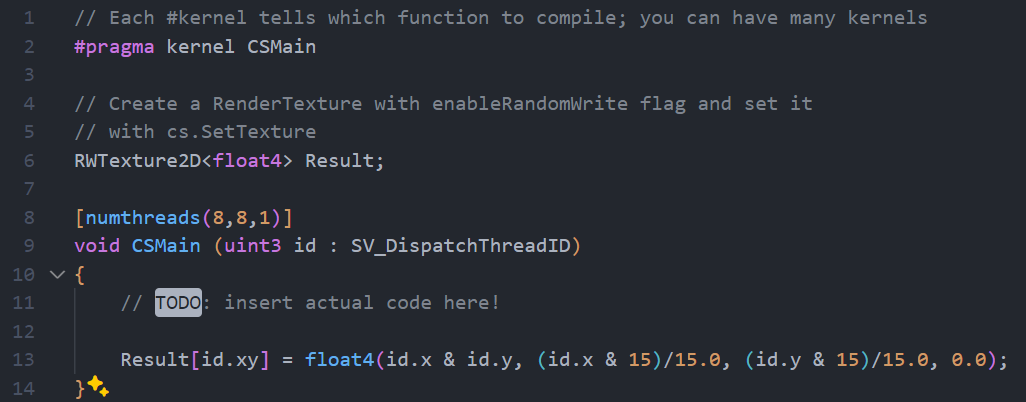
#pragma kernel CSMain代表的是 compute kernel,這個 kernel 會對應到檔案中的一個函式名稱。一個檔案可以定義多個 kernel,也就是多個#pragma kernel 函式名稱,這樣你可以全部塞同個檔案,之後要用的時候就在 C# callshader.FindKernel(函式名稱)就好。RWTexture2D<float4> Result;是一個可以讀寫的 Texture,GPU 可以把算好的資料存進去,之後拿來用[numthreads(8,8,1)]是你宣告一個 Thread Group 中有幾個 Thread,等等會詳細介紹void CSMain (uint3 id : SV_DispatchThreadID)- CSMain 是你函式的名稱,也就是前面
#pragma kernel對應到的函式 SV_DispatchThreadID是你當前 Thread 的 ID,這樣 GPU 才知道現在在算哪一個 Thread 的內容
- CSMain 是你函式的名稱,也就是前面
Result[id.xy] = float4(id.x & id.y, (id.x & 15)/15.0, (id.y & 15)/15.0, 0.0);是你在這個 Thread 會寫進 Texture 的內容,可以看到這邊藉由 SV_DispatchThreadID 來判斷要寫進 Texture 的哪個位置
C# 端
1 | |
在這邊,我會傳入先前建立的 Compute Shader 和 RenderTexture。
computeShader.FindKernel("CSMain");能夠去尋找對應的 kernel,並回傳一個 kernel index 之後做使用computeShader.SetTexture(_kernelIndex, "Result", renderTexture);綁定計算的資源。這邊的 “Result” 是對應到 Compute Shader 檔案裡的RWTexture2D<float4> Result;。這邊在做的事情就是把 Result 的資料 Bind 到我自己的 Render Texture 上面,也就是說我更新 Result 等同於更新我的 Render Texture。computeShader.Dispatch(_kernelIndex, renderTexture.width / 8, renderTexture.height / 8, 1);這個就是去啟動 Compute Shader,並宣告要有幾個 Thread Group,之後會詳細介紹。
到目前為止,程式碼的部分已經完成,剩下一些步驟
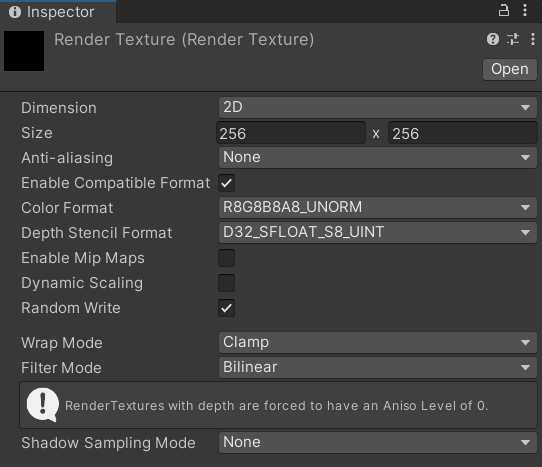
記得要勾選 Random Write,這樣這個 Texture 才能支援 Random Access
隨便個物件,塞入我們剛剛建立好的 assets,並執行它

遊戲開始的時候可以看到我們的 Render Texture 長相變了!上面的顏色就是你 Texture 上每個 Texel 的 RGB 值,也就是 Unity 預設的 Result[id.xy] = float4(id.x & id.y, (id.x & 15)/15.0, (id.y & 15)/15.0, 0.0);,float4 的四個參數就是 RGBA。這樣的結果代表你的 Compute Shader 確實有執行,並且成功把結果寫進你的 Texture 裡面。
Thread 執行緒
先來補一下剛剛挖的坑,也就是 numthreads(8,8,1) 和 computeShader.Dispatch(_kernelIndex, renderTexture.width / 8, renderTexture.height / 8, 1) 到底在做什麼
我們知道 GPU 具有強大的平行計算能力,那是因為 GPU 含有成千上萬個 Thread,每個 Thread 都能執行一個小程式。在 Compute Shader 中,一個 Kernel 會被分配到一堆 Thread 上面去執行 (像是剛剛的 CSMain),因此我們要告訴 GPU 現在需要幾個 Thread。
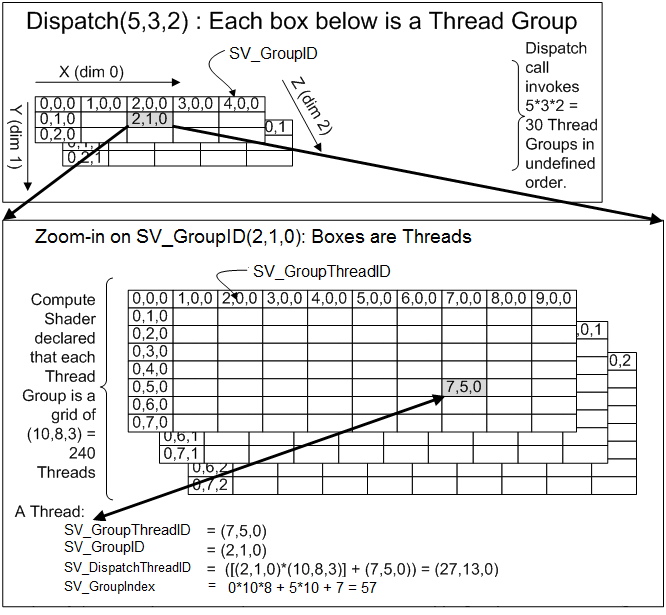
而在 GPU 中,一群 Thread 可以組成 Thread Group,一群 Thread Group 可以組成 Grid,且 Thread Group 和 Grid 都是三維的架構。因此
numthreads(8,8,1)就是告訴 GPU 這個 Thread Group 的 XYZ 軸分別有幾個 Thread。computeShader.Dispatch(_kernelIndex, renderTexture.width / 8, renderTexture.height / 8, 1)就是告訴 GPU 這個 Grid 的 XYZ 軸分別有幾個 Thread Group
這樣的架構能讓我們更方便管理和使用計算的資源,所以這邊我就根據我的 Render Texture 解析度,來去分配 Thread 的數量
Uniform Data
在 CPU 端除了綁定資源以外 (buffer、texture),你也可以傳入一些 Uniform Data,這些 Data 在這次計算的時候是不會改變的,作為一個 Constant 來使用。
舉個例子,我現在想讓 GPU 有 float Time 可以使用,我想讓 Texture 的 G 值隨著時間去做改變
Shader 端
C# 端
1 | |
結果
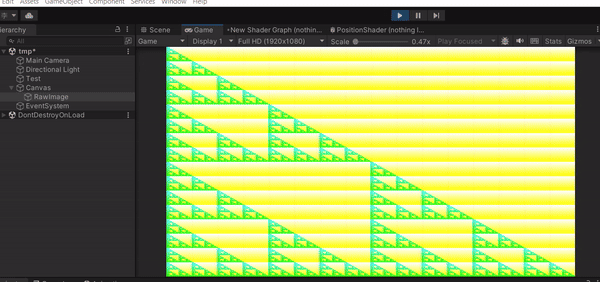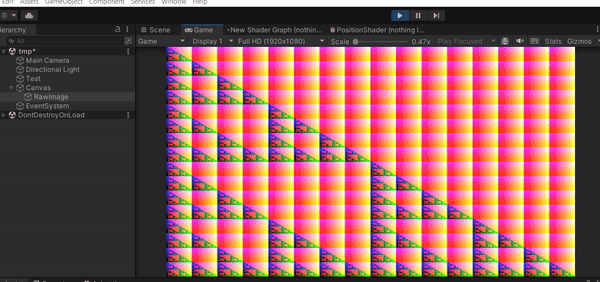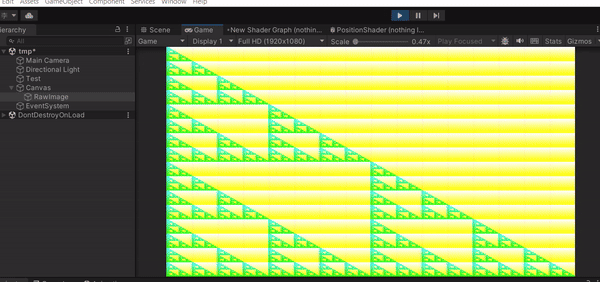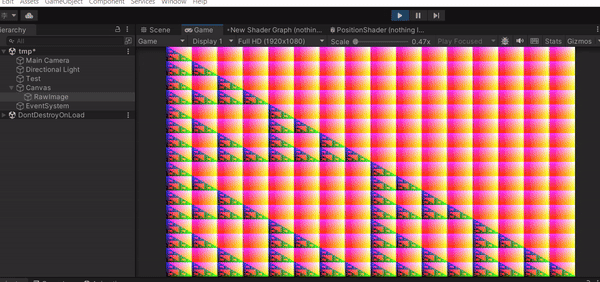
現在你已經知道怎麼在 Unity 中建立並啟動 Compute Shader,並輸出一個簡單的結果,你也可以試著改改看 Compute Shader 的內容,輸出各種不同的結果
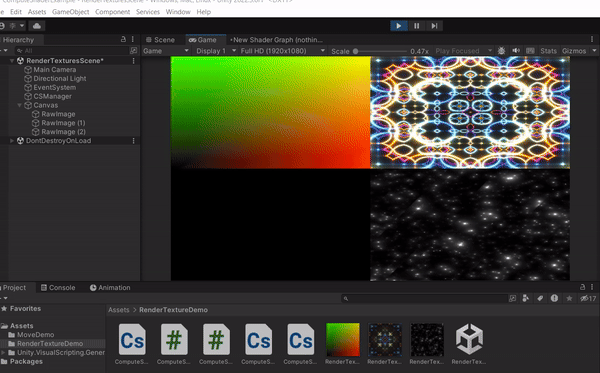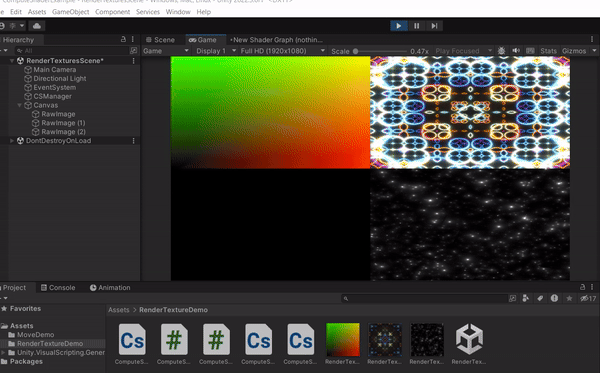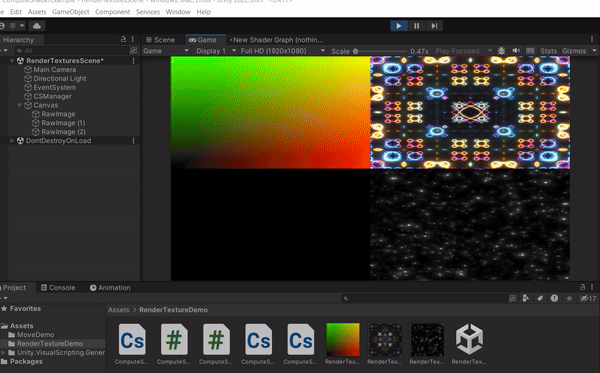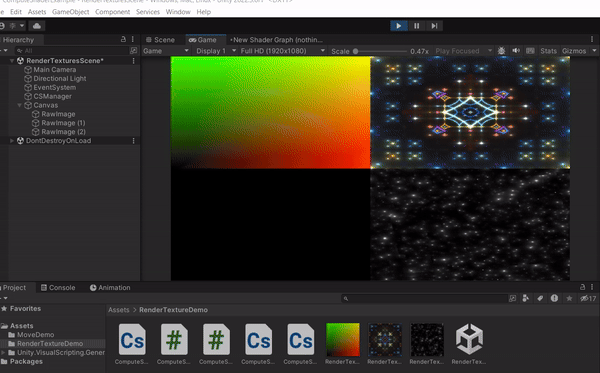
以上這些都是透過 GPU 去計算出來的結果,更多範例可以參考 Shader Toy,不過要注意的是這網站使用的語言是 GLSL,而且是寫在 Fragment Shader 上面,這裡提供的例子使用的語言是 HLSL,而且是寫在Compute Shader上面。接下來會介紹更多 Compute Shader 的應用方式
移動大量物體
現在,先定個目標:我希望在場景中渲染 16384 個物件,並同時移動它們,某物件的下一個位置是根據當前位置去計算的,因此彼此之間不會互相影響。
這裡我提供四種不同的方法,逐漸優化遊戲的效能。
一般寫法
最一般的寫法很直覺,直接在 Start() 建立 16384 個物件並儲存起來。接著,在 Update() 中開個 for 迴圈遍歷所有物件,根據當前位置去改變物件下一偵的位置
C# 端
1 | |
效果
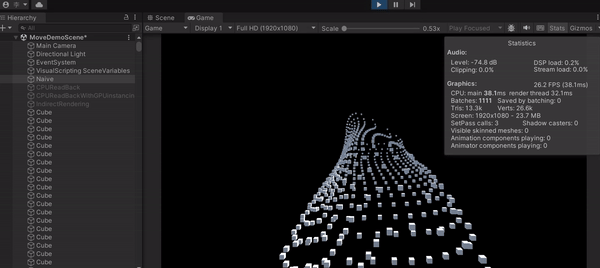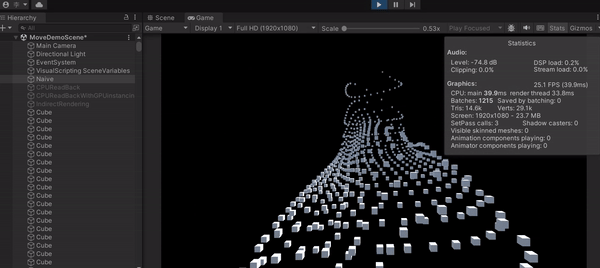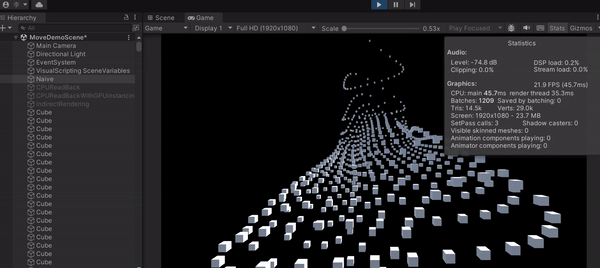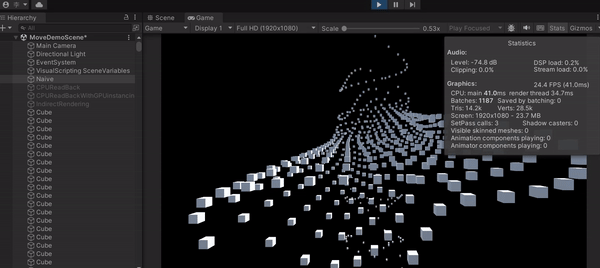
可以發現這種直白作法的 FPS 差不多是 24 FPS,代表一秒只能畫 24 張,最主要原因就是 CPU loading 太大,拖累了進度
比較好的做法 (Compute Shader + CPU Read Back)
第二種做法是把計算所有物件位置的任務丟給 GPU 去算,算出每個物件下一個位置的資料,最後 CPU 只要負責等待結果回傳,根據 GPU 算好的資料去更新物件的位置
Shader 端
1 | |
這邊有一個 Buffer,內容包含所有物件的位置,接著根據當前位置去計算下一個位置,再存回 Buffer 即可。
C# 端
1 | |
我們在 Start() 的地方宣告一個 Buffer,內容包含剛開始所有物件的位置,接著就是傳入資料,啟動 Compute Shader。在 Update() 裡面的 GetData() 可以 Block 下面的程式碼,也就是直到 GPU 算好後才繼續往下執行操作,避免發生 GPU 還沒算好 CPU 就讀取的情況。
注意,這裡我宣告 16 個 Thread Group,每個 Thread Group 有 1024 個 Thread,一共有 16 * 1024 = 16384 個 Thread,剛剛好等於我們擁有的物件數量,也就是說每個 Thread 就負責處理一個物件的位置。
只要最後數量對就好,有幾個 Thread Group、每個 Thread Group 有幾個 Thread 不是很重要。為了方便,我只宣告在 X 象限,這樣讀取 Buffer 的時候可以直接用 CubeBuffer[id.x] 就好,不用管 id.y、id.z
效果
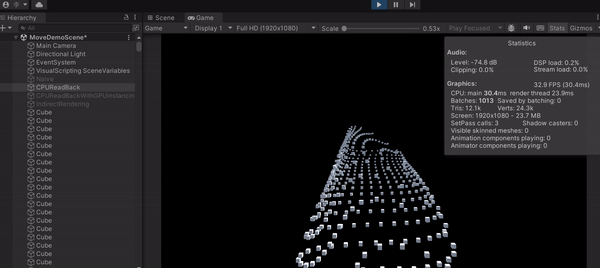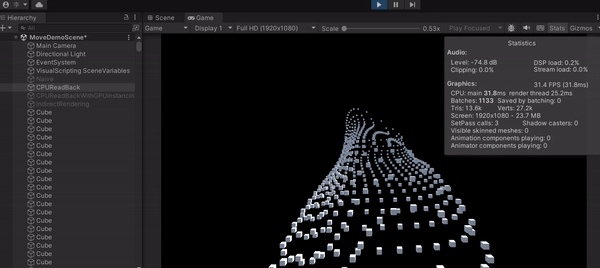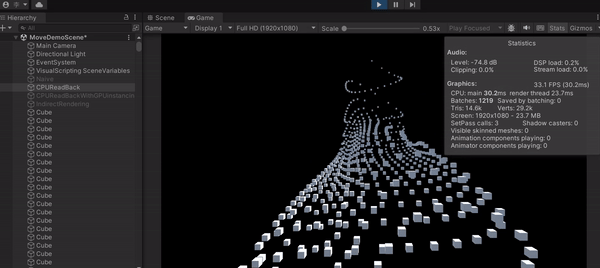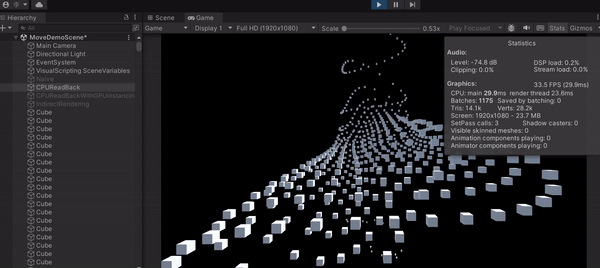
可以發現這種作法的 FPS 有些許上升,來到了 32,代表一秒可以畫 32 張,但是上升的很不明顯,最主要就是因為 CPU 在等 GPU 算完才繼續執行,白白浪費時間在那邊掛機。雖然 GPU 確實算很快,但這作法不能完全發揮 Compute Shader 的功力
GPU Instancing
這邊先介紹一個跟 Compute Shader 比較沒關的優化方法,也就是 GPU Instancing。當我們想繪製大量且相同的 Mesh 時,可以用這種方法。
Draw call
在 Unity 中,CPU 命令 GPU 去繪製 Mesh + Material 的步驟就是 Draw Call,當場景中有大量物件時,意味這我們會有很多 CPU 命令 GPU 做事的步驟,但是這是一件非常花時間的事情
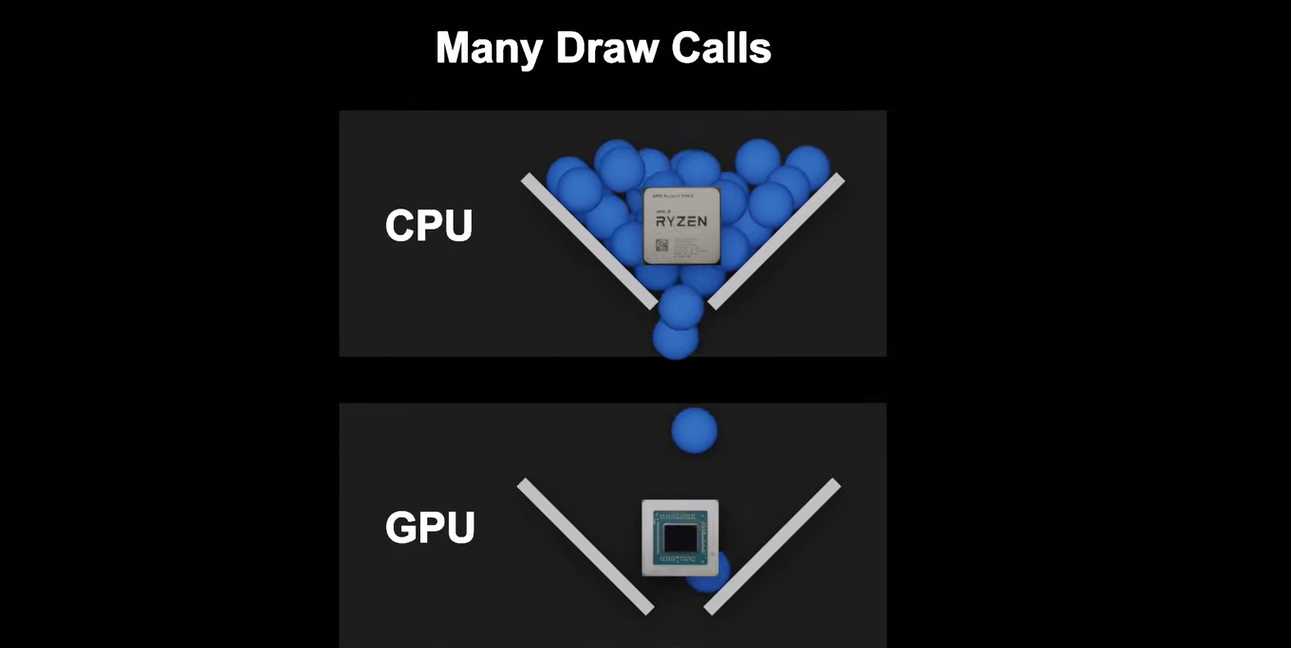
既然我們要畫 Mesh 和 Material 都一樣,為什麼不畫一次就好?GPU instancing 的概念就像是告訴 GPU 說:「嘿,這些方塊都長得一樣,你只要畫一次,然後把它們放到對的地方就好。」,這樣就不需要重複告訴 GPU 如何畫每個方塊,而是告訴 GPU 如何畫一個方塊,然後告訴它在哪裡重複使用這個畫好的方塊。這種做法可以大幅提高效能。
Shader 端
跟這邊沒關係,所以跟第二個做法一樣,不用改
C# 端
1 | |
這邊就不詳細介紹程式碼,有興趣可以去看 Unity GPU Instancing in less than 7 minutes! 的教學。
簡單來說就是把一些物件打包成一個個 Batch(DrawMeshInstanced一個 batch 只能塞 1023 個東西,所以這邊讓他超過 1000 的話就裝進下個 batch)。然後把每個物件的 Transform Matrix 算好,之後就傳給 GPU 去移動位置。
效果
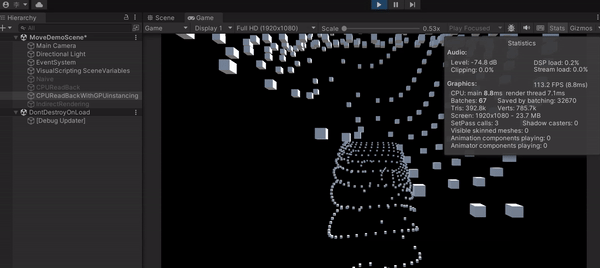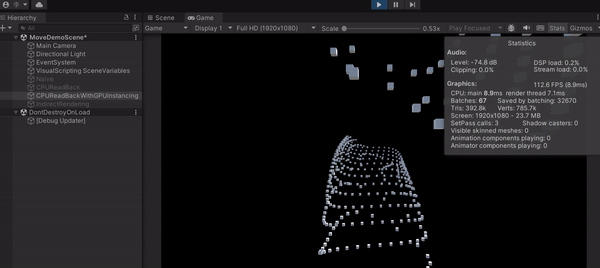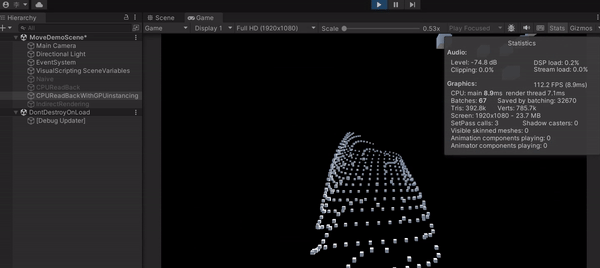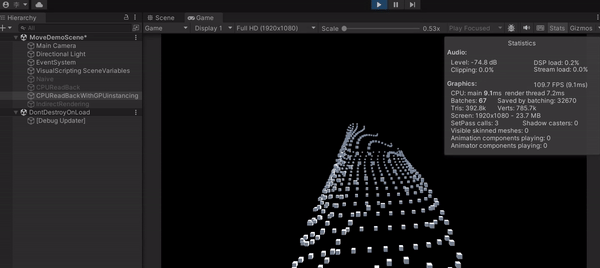
可以發現這種作法大幅提升了效能,FPS 竟然能上升到 110 左右,可見 Draw Call 是多可怕的東西,這也叫做 CPU Bottleneck。另外,上圖中的 Batches 就是 Draw Call 的數量,從原本的 1000 多減少到 67。
然而,我們還沒發會 Compute Shader 真正的功用,這不是最快的,我們要更快,還要再快
Indirect Rendering
仔細想想,我們第三種作法的流程是
- CPU 宣告 Buffer,傳給 GPU (Compute Shader)
- GPU (Compute Shader) 算好新的位置,傳給 CPU
- CPU 掛機耍廢,直到 GPU 算好回傳 CPU 才接收新位置的資料
- CPU 把剛接收的資料傳給 GPU 去渲染
有沒有覺得哪裡怪怪的?CPU 耍廢到接收資料,剛收到又傳回 GPU??為什麼不直接全部交給 GPU 做就好,可以減少 CPU 和 GPU 之間的溝通成本,還可以讓 CPU 去忙其他事情,Indirect Rendering 就是這種概念。
為了讓 GPU 直接讀取新位置資料,去更新當前位置,我們會需要自己寫 Vertex Shader。Vertex Shader 就是運行在 GPU 上,用來控制每個 Vertex 的相關訊息。想法就是,Compute Shader 算好後存在 Buffer 中(Buffer 就是一段記憶體),接著我們讓 Vertex Shader 直接去讀取這段記憶體位置,直接取得 Buffer 裡面的內容,更新 Vertex 的位置,省略掉 CPU 等待、回傳的步驟,全程都在 GPU 上面執行。
Compute Shader 端
不用改
Vertex Shader 端
1 | |
這裡就不介紹 Vertex Shader 怎麼寫了,因此省略掉很多程式碼,只是想表達我讀取 Buffer,並做成 Transform Matrix 去更新頂點位置的過程
C# 端
1 | |
跟第三種作法不同的地方是,我的 GPU instancing 換成 RenderMeshPrimitives,因為我要自己寫移動 Vertex Shader 的程式碼,而且 RenderMeshPrimitives 沒有 Batch Size 的限制,會是更好的選擇。
效果
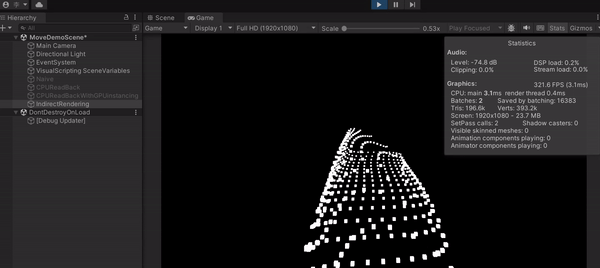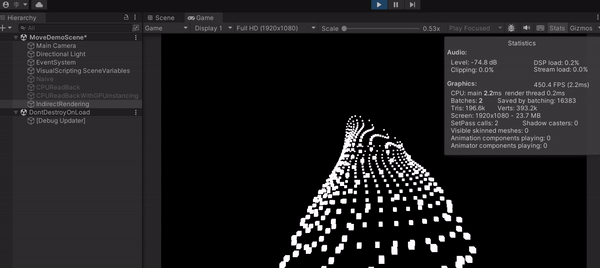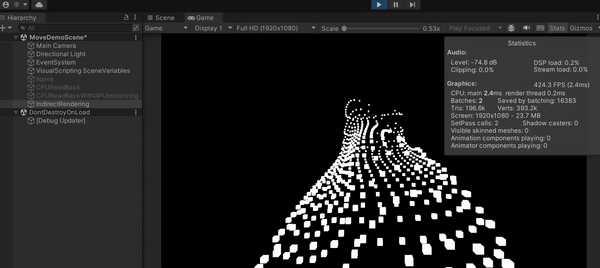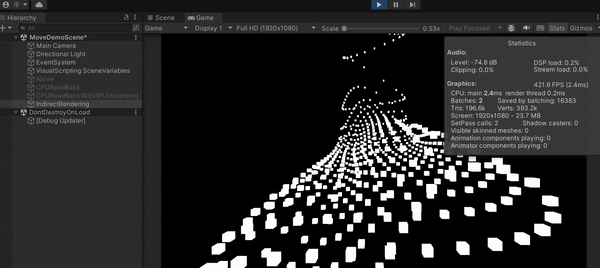
透過這種作法,可以看到我的 FPS 上升到 400 左右,畫面順到不行,不說我還以為我的 CPU 特別猛(GIF 看起來會比較卡,最後有附上影片)
不過這種作法也有缺點,就是不能辨別碰撞、Culling 等等,因為實際上物體並沒有移動,只有物體的頂點移動而已,不過這也可以透過其他方式解決,只是原本 CPU 會幫你弄好,現在要自己寫比較麻煩而已,但是效能會好上許多。
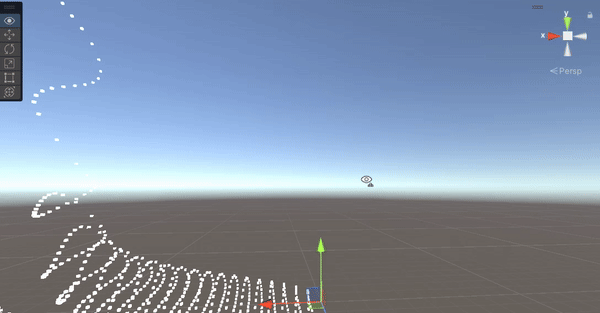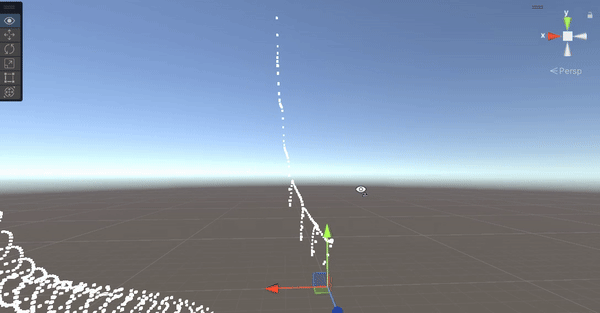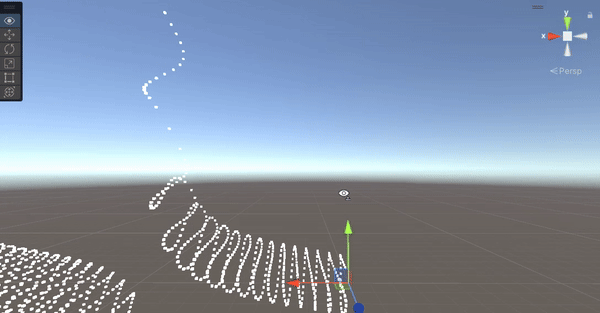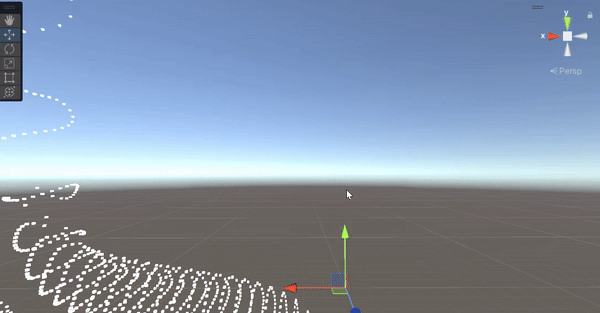
像上面這個例子,物體原本的位置沒有移動,只有頂點在移動,因此當原本的位置跑到鏡頭外面,會直接被 Culling 掉,只能自己寫判斷了。
以上是本篇教學,花費我許多時間,不過我也因此學到很多東西。
我認為 Computer Shader 真的是一項值得深入探討的技術,像是原神渲染技術分享中就有提到,有超過一半的 Feature 都有使用到 Compute Shader 優化。了解遊戲背後的技術是一件很有趣的事情,這樣玩遊戲跑圖的時候都可以想到一些有的沒的,偷偷思考場景看到的特效背後的原理
後來發現上面的例子可能沒有真的到 16384 個物件,有些太遠的都被 Culling 掉了 qq,感謝你看到這邊