Machine Learning - Basic Concepts
惡補 ML https://www.youtube.com/watch?v=Ye018rCVvOo&list=PLJV_el3uVTsMhtt7_Y6sgTHGHp1Vb2P2J
機器學習基本概念
機器學習的核心是讓機器根據資料學習一個模型(function),讓新的輸入做出相對的預測或決策。
分類
- Regression
- ex: 預測東西
- Classification
- ex: Alphago
- Structured Learning
- 創造東西,ex: 生成式?
機器學習的 Framework
找 Model ,ex:$y = b + wx$
- 帶有未知 parameter 的 function 稱為
Model - $x$ 稱為
feature,為 輸入給模型的資料 - $w$ 稱為
weight - $b$ 稱為
bias
- 帶有未知 parameter 的 function 稱為
定義
Loss Function,ex: $L(b, w)$- 假設一開始是 $b = 0.5$、$w = 1$,就以 $y = 0.5 + 1x$ 來算出
每一筆資料的計算結果與label之間的誤差 $e$- 實際上正確的 $y$ 稱為
label
計算誤差的方法有很多,像是- MAE(Mean Absolute Error): $e = \lvert y - \hat{y} \rvert$
- MSE(Mean Square Error): $e = (y - \hat{y})^2$
- Cross-entropy
- 實際上正確的 $y$ 稱為
- 算好後把每個 $e$ 套入
Loss Function- ex: $L = \frac{1}{N}\Sigma_{n}e_n$
- 假設一開始是 $b = 0.5$、$w = 1$,就以 $y = 0.5 + 1x$ 來算出
Optimization,找到 $w$ 和 $b$ 能夠讓
Loss Function算出最小的值- Gradient Descent
- 隨便選一個 $w_0$、$b_0$
- 計算斜率,以 $w$ 為例,$\eta \cdot \frac{\partial L}{\partial w}|_{w=w^0, b=b^0}$
- $\eta$ 是
learning rate,需要自己設定- 這種要自己設定的值稱為
hyperparameter
- 這種要自己設定的值稱為
- $\eta$ 是
- 更新 $w$ 和 $b$,以 $w$ 為例,$w^1 = w^0 - \eta \cdot \frac{\partial L}{\partial w}|_{w=w^0, b=b^0}$
- 持續更新,最後 $L$ 會接近
local minimum或global minimum附近
- Gradient Descent
實際上在算 Gradient 的時候,不會每次都拿所有訓練資料去算,會把所有訓練資料隨便分成很多 Batch,每次都拿一個 Batch 算出 Gradient,叫做一次 update,如果把所有 Batch 都看過一輪,叫做一個 epoch
此外,上面的 Model 是定為 $y = b + wx$,但實際上這種 Linear Model 可能不足以描述現實情況,也就是 Model 不夠力,稱為 Model Bias,這時候可以加入更多 Feature,定出一個更複雜的 Model
- Piecewise Linear
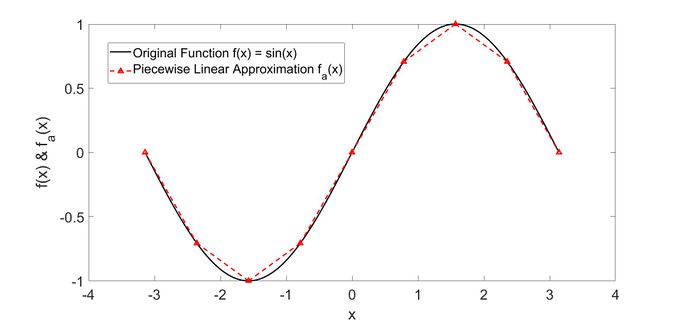
現實中可能是 Continuous Function,可以用 Piecewise Linear 來模擬,Piecewise Linear 又可以用很多不同的 Hard Sigmoid 來組合出來,而 Hard Sigmoid 又可以由 Sigmoid Function 模擬出來

- Sigmoid Function
$$c \cdot sigmoid(b+wx_1) = y = c \cdot \frac{1}{1+e^{-b+wx_1}}$$
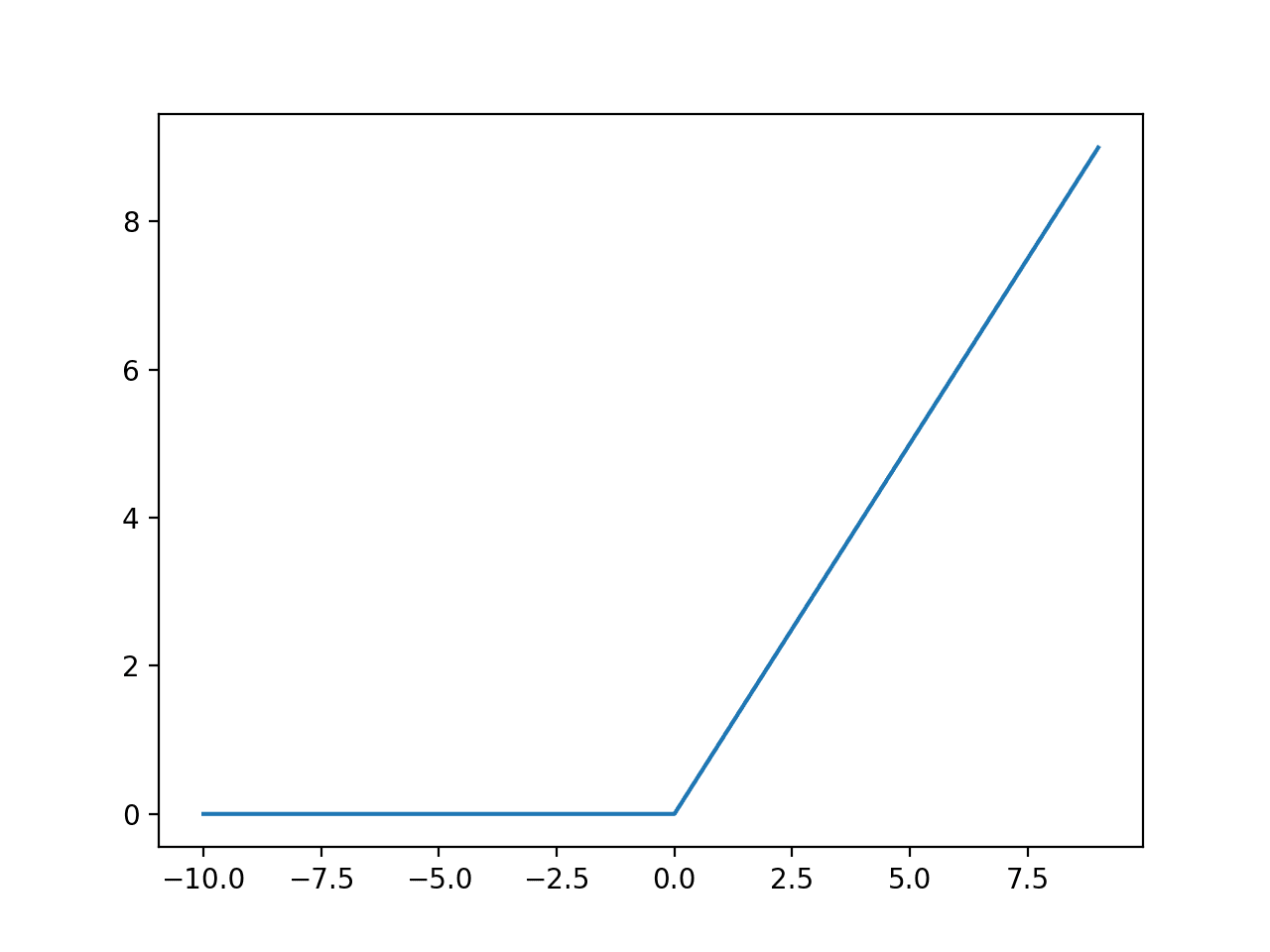
Hard Sigmoid 也能用兩個 ReLU (Rectified Linear Unit) 算出
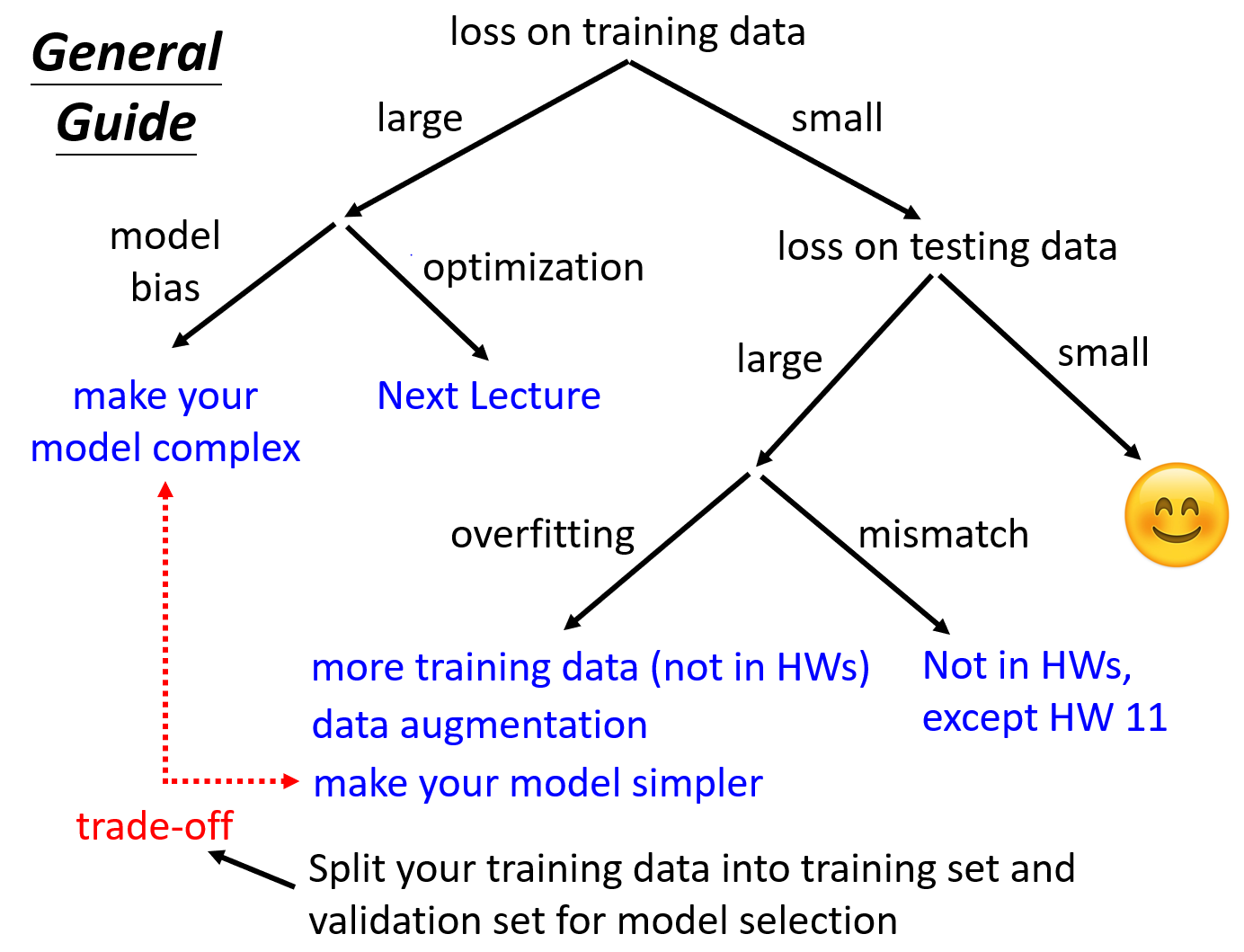
機器學習的任務攻略
Model Bias
模型不給力Optimization
可能是 Optimization 的方式有問題,像是Gradient Descent不給力
透過比較不同模型的來區分是不是 Model 的問題
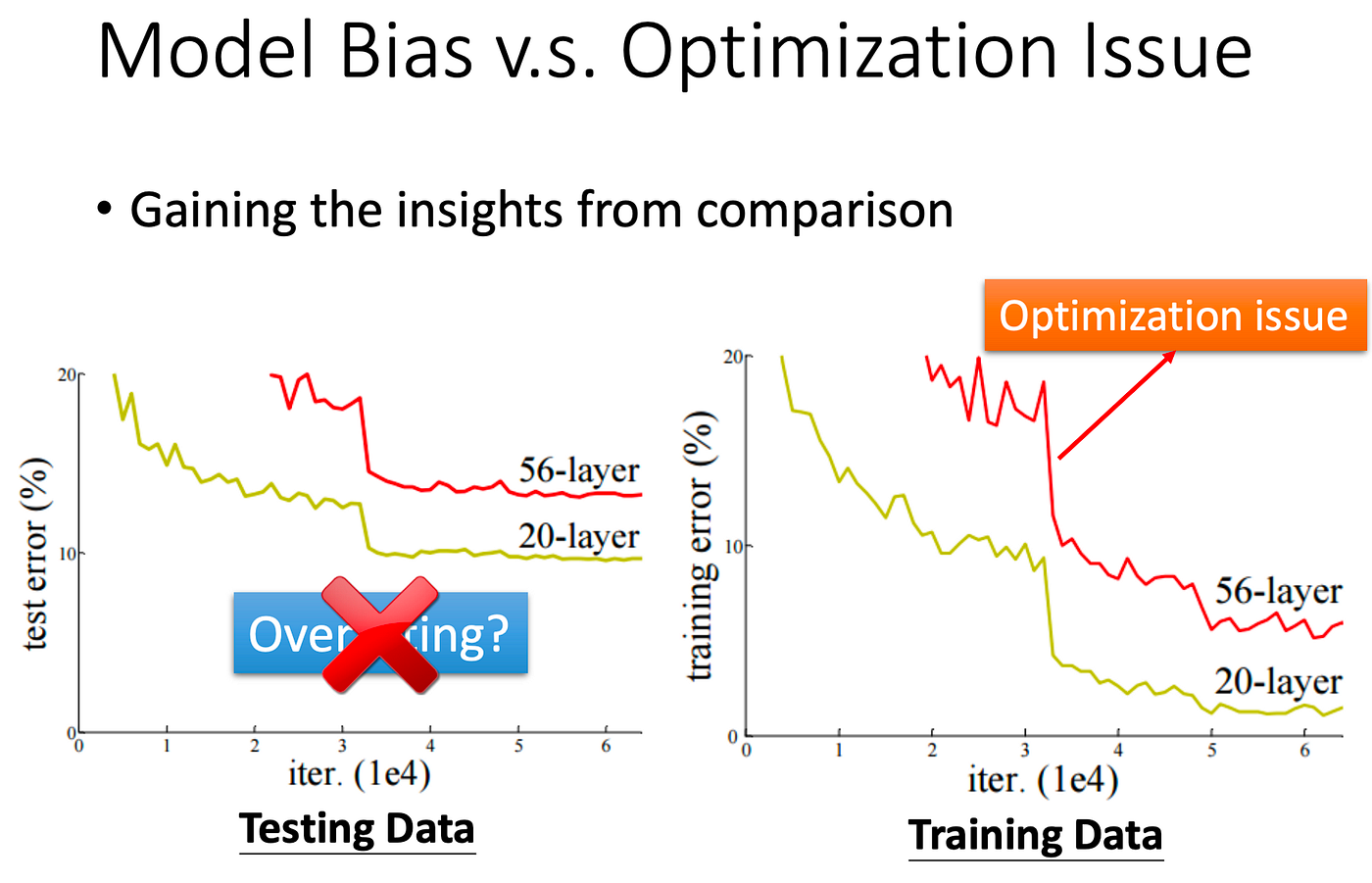
像這個例子中, 20-layer 在 Traning Data 上表現的還比 56-layer 好,就可以知道是 Optimization 的問題。可以先測比較淺的 Model 或是比較簡單的 Model,比較不會有 Optimization 的問題。
- Overfitting
Traning Data 表現好,Testing Data 表現很爛- 增加 Traning Data
- Data augmentation
根據理解創造出新的資料,ex: 翻轉圖片、放大圖片等 - 限制模型,不要讓他彈性那麼大,ex: 減少
Feature、減少Parameter、Sharing Parameter、Early Stopping、Regularization、Dropout 等