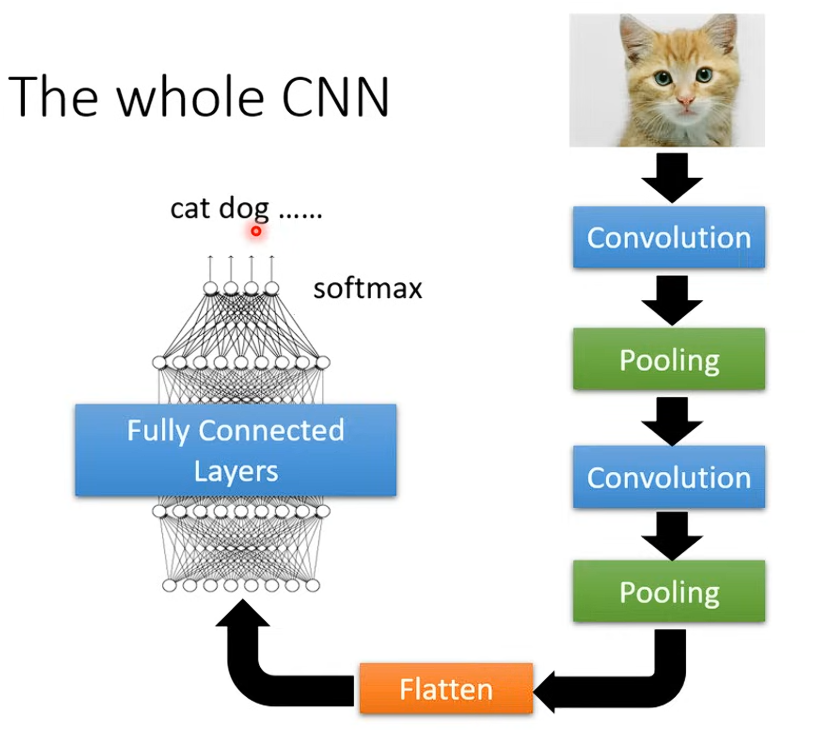
Machine Learning - CNN
惡補 ML https://www.youtube.com/watch?v=Ye018rCVvOo&list=PLJV_el3uVTsMhtt7_Y6sgTHGHp1Vb2P2J
Convolutional Neural Network (CNN)
如果用 Fully Connected Network 的方式來做圖片的分類,會有很多參數,雖然可以增加 Model 的彈性,但也會增加 Overfitting 的風險
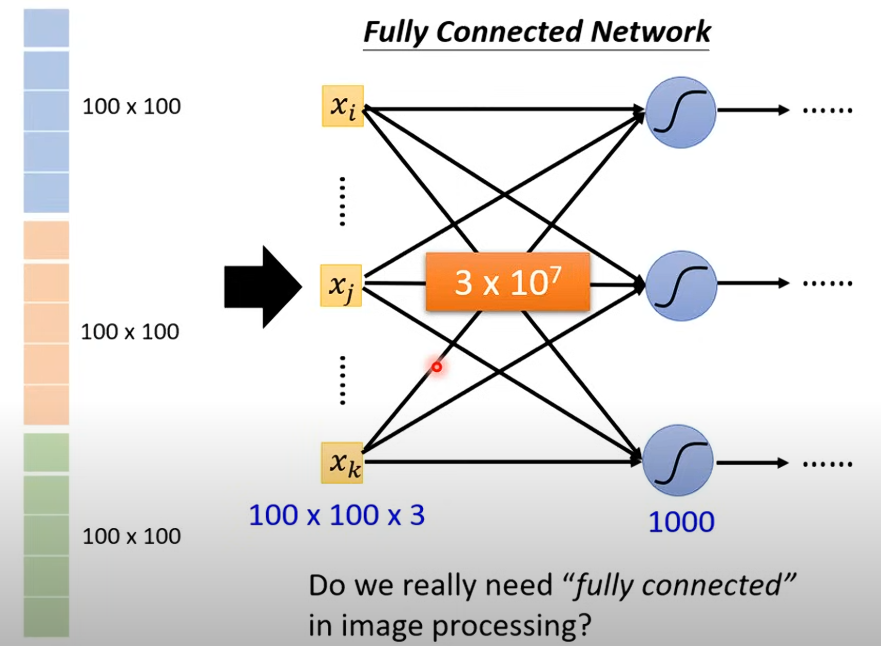
像上圖這個例子,圖片大小是 100 x 100,算上 RGB 三個 Channel,就有 100 x 100 x 3 個 Feature,第一層有 1000 個 Neuron,每個 Neuron 對於這 100 x 100 x 3 個 Feature 都有一個 Weight,所以總共有 100 x 100 x 3 x 1000 個 Weight
Receptive Field
然而對於圖片辨識來說,他只在乎圖片有沒有重要的 Pattern,因此這些 Neuron 其實不用把整張圖片當作輸入,只要關心自己的 Receptive Field 就好
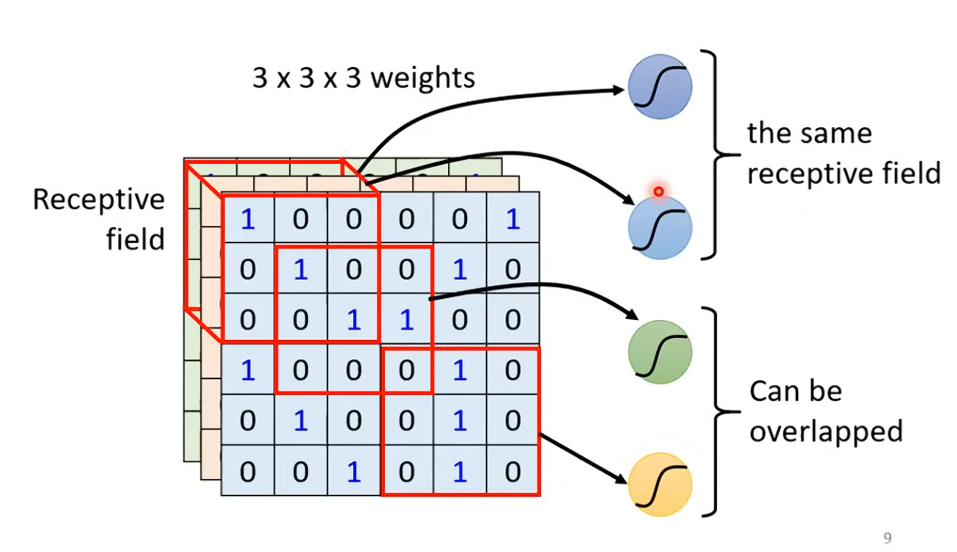
典型的設置方式是像下圖
- 會檢查所有
Channel Kernel Size:3 x 3Stride: 通常是1或2,避免有些Pattern被忽略- 超出去的部分要補
Padding - 每個
Receptive Field會有一組Neuron看著
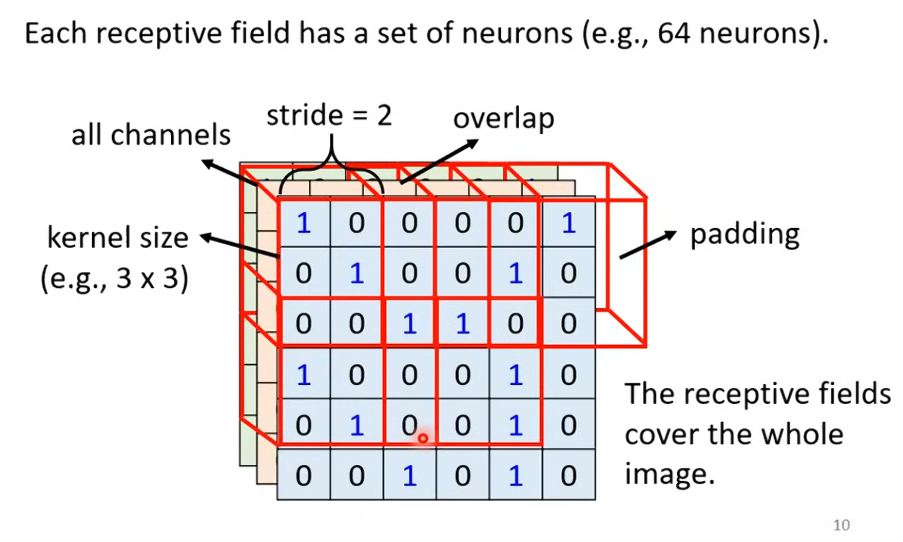
雖然 Kernel Size 只有 3 x 3,但當 Model 疊的越深,每個 Receptive Field 就會看到更大的 Pattern,不用擔心太大的 Pattern 偵測不到
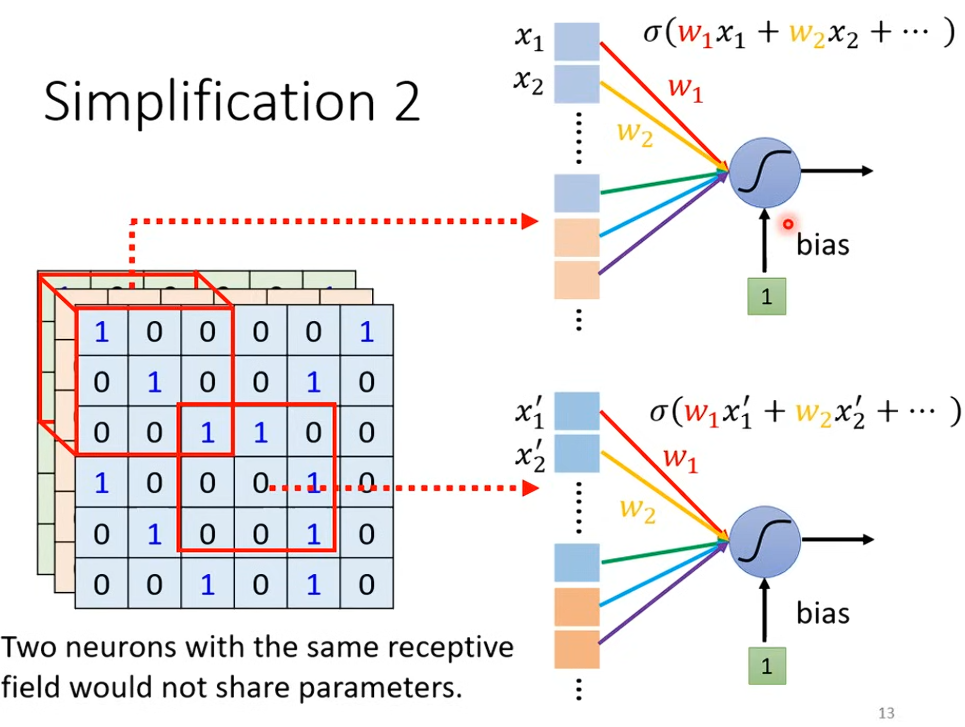
Shared Parameter
有時候同樣的 Pattern 會在不同圖片的不同位置出現,這些 Neuron 做的事情其實是一樣的
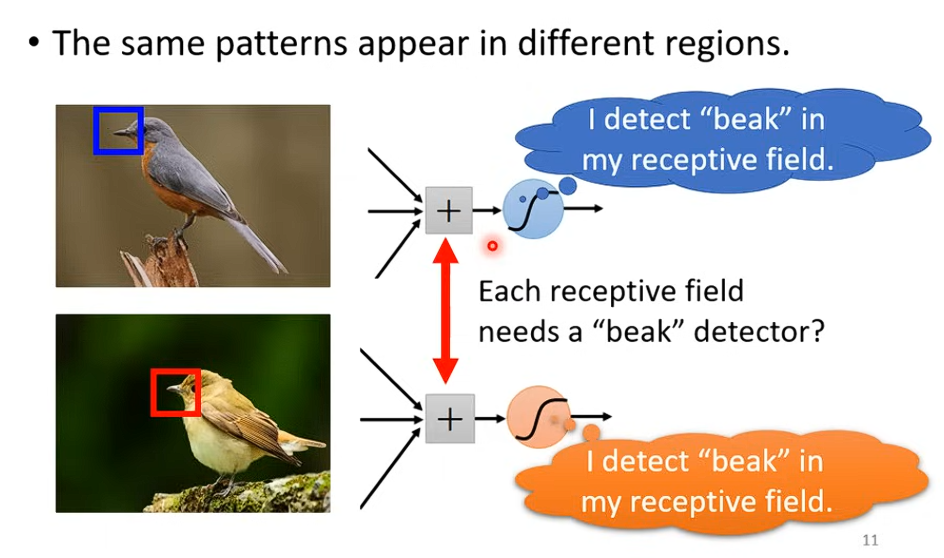
這時候可以用 Shared Parameter 來解決,讓不同的 Receptive Field 的不同 Neuron 用同樣的 Weight,減少參數。(在實作上,其實就是一個 Filter 掃過整張圖片)
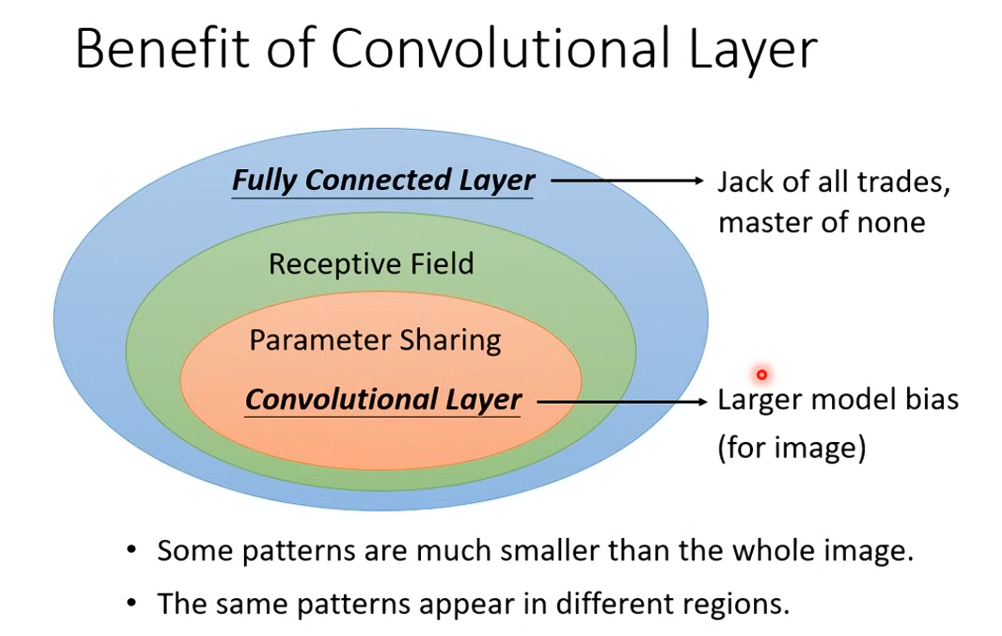
Fully Connected Network 很彈性,可以做各式各樣的事情,但可能沒辦法在任何特定的任務上做好。CNN 則是專注在圖片辨識上,即使 Model Bias 比較大,比較不會 Overfitting
Pooling
有時候為了減少運算量,會用 Pooling 來做 Subsampling,通常是 Max Pooling 或 Average Pooling

一般都是在 Convolutional Layer 後面接 Pooling Layer,交替使用
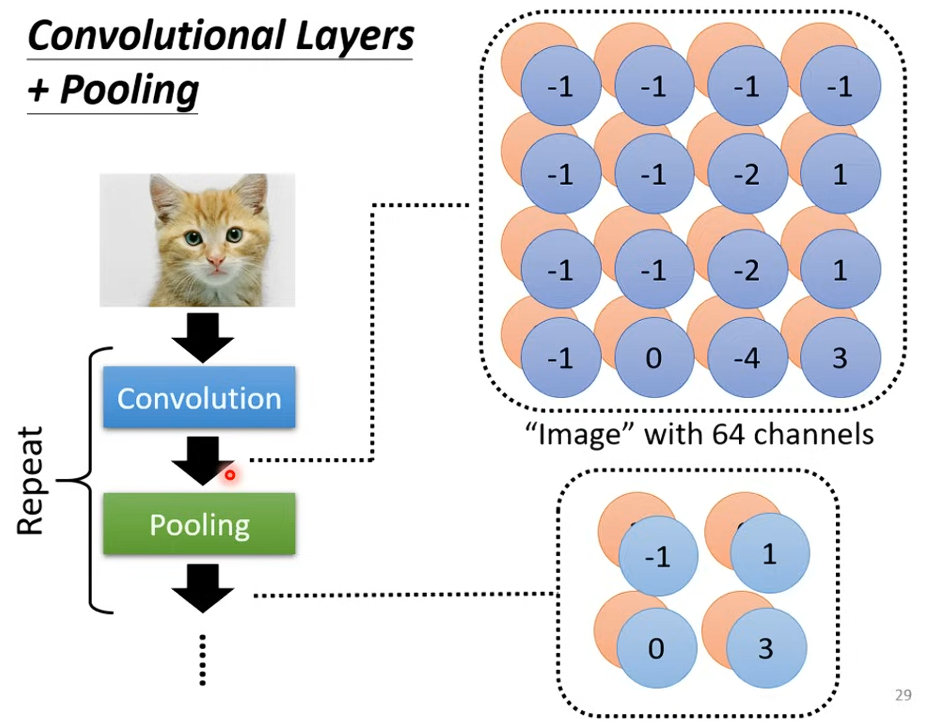
不過 Pooling 可能會造成 Information Loss,有些比較細微的特徵會偵測不到,因此也有人從頭到尾都只用 Convolution,像是 AlphaGo
CNN Structure
在 CNN 中 Convolutional Layer 和 Pooling Layer 的最後,Flatten 過後會再接幾層 Fully Connected Layer,再接一個 Softmax 來做分類