Machine Learning - Self-Attention & Transformer
惡補 ML https://www.youtube.com/watch?v=Ye018rCVvOo&list=PLJV_el3uVTsMhtt7_Y6sgTHGHp1Vb2P2J
Self-Attention
先前提到的 Input 都只是一個 Vector,然而很多時候,模型吃的是 一組 Vector,又稱 Vector Set、Sequence,又可以分成三類
- 每個
Vector有一個Label,輸入的數量等於輸出的數量,稱為Sequence Labeling- ex:
Pos-Tagging
- ex:
- 整個
Sequence只有一個Label- ex:
Sentiment Analysis
- ex:
- 機器自己決定要有幾個
Label- ex:
Sequence-to-Sequence、Machine Translation
- ex:
對於 Sequence Labeling,如果像前面提到的 CNN 一樣,每個 Vector 都是獨立的,可能會忽略掉 Vector 之間的關係 (Context)。你也可以把整個 Sequence 丟到 CNN 裡面,但參數量、計算量都會超大,又久又容易 Overfitting,因此有了 Self-Attention
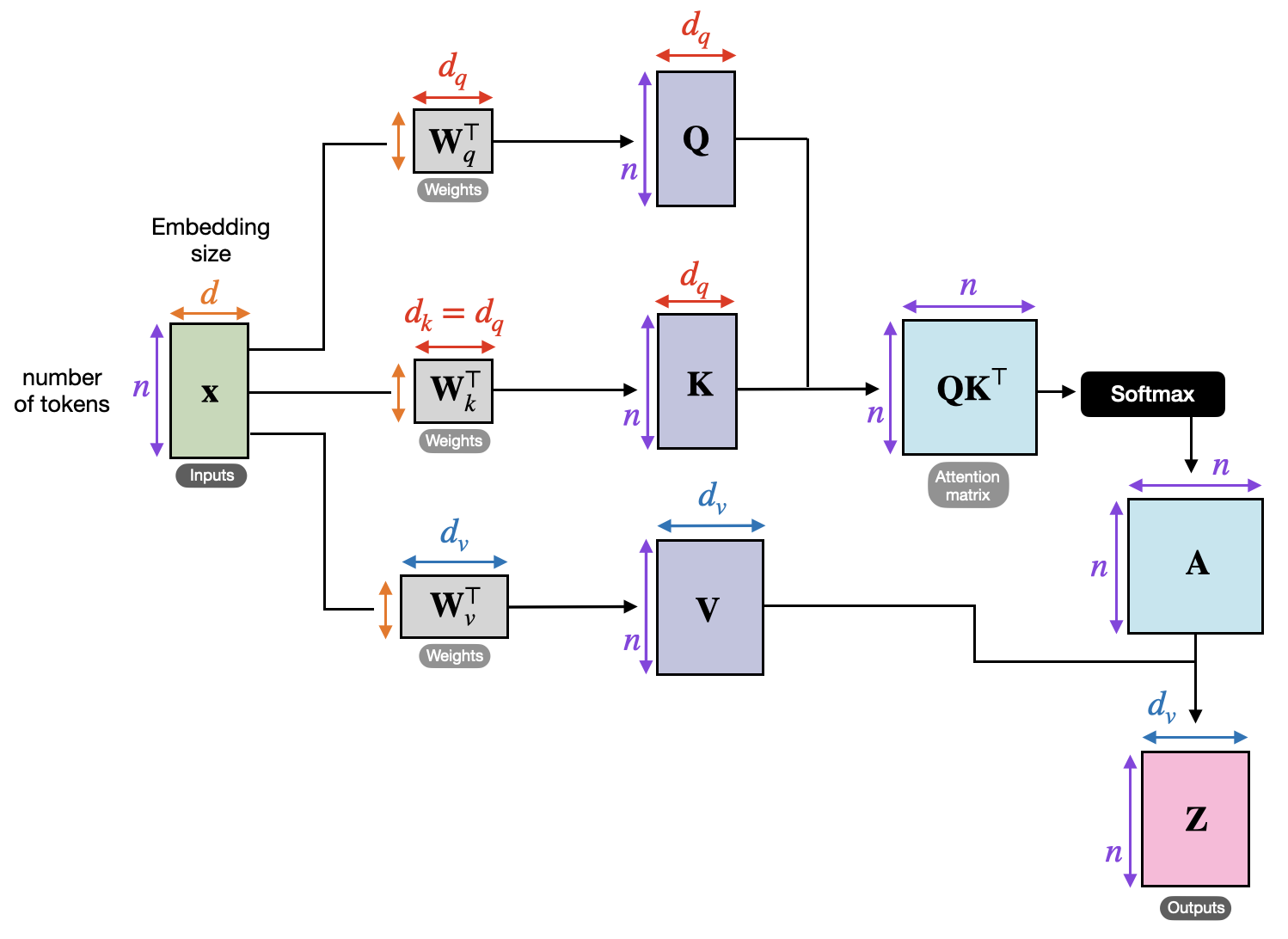
Self-Attention 的概念是,對於每個 Vector,都會有一個 Query、Key、Value,然後透過 Query 和 Key 的 Dot Product 來計算 Attention Score,再透過 Softmax 來計算 Attention Weight,最後再把 Value 乘上 Attention Weight 來得到 Output
Softmax是最常見的,不過也可以用別的Activation FunctionAttention Weight會讓Model知道哪些Vector是重要的,哪些是不重要的
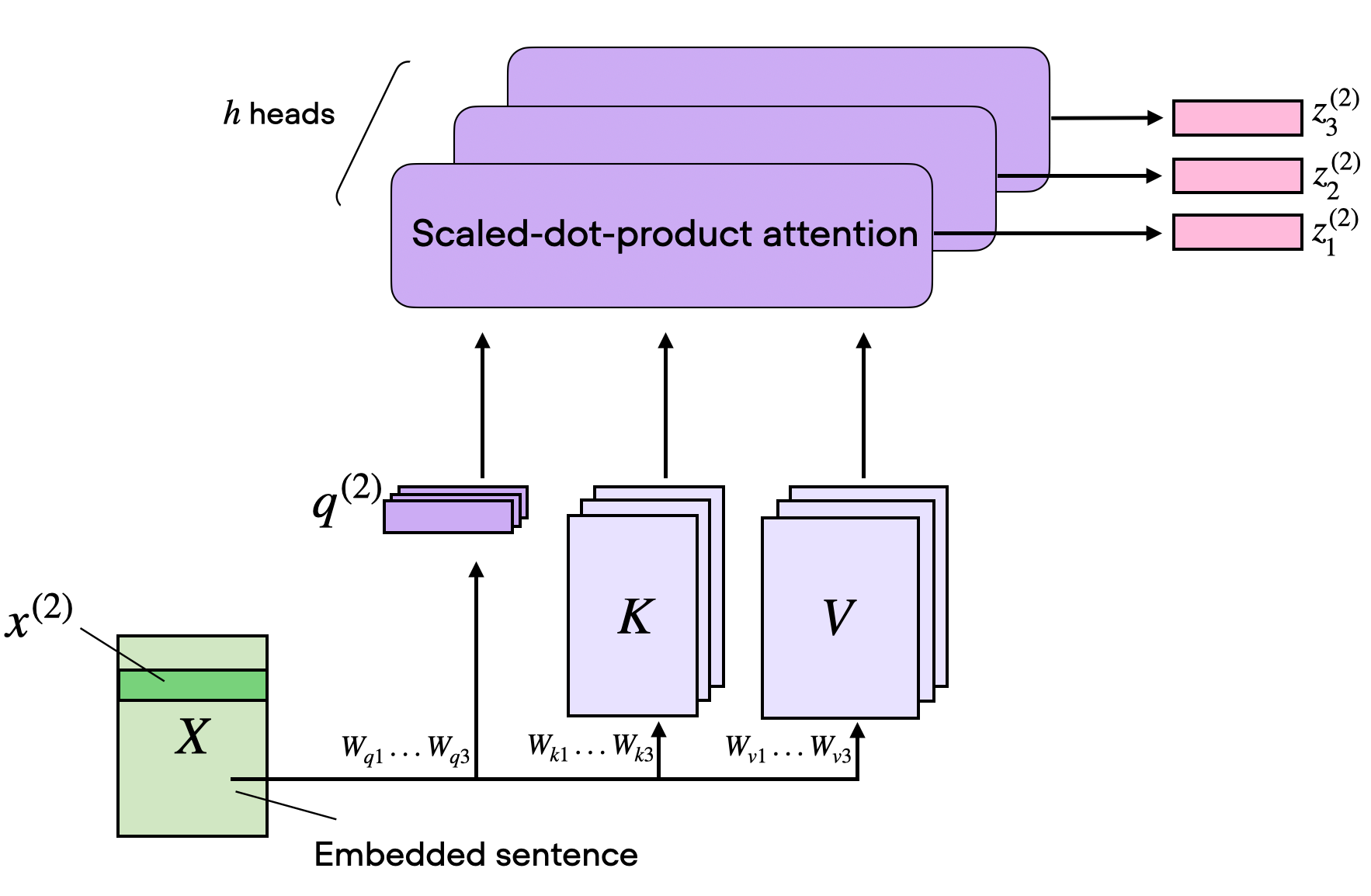
Multi-Head Self-Attention
相關這件事情可能有很多種形式,為了要找到資料中不同種類的相關性,可以用 Multi-Head Self-Attention
- Head 的數量也是
Hyperparameter
Positional Encoding
Self-Attention 並不會考慮到 Position,因此需要加上 Positional Encoding,讓 Model 知道 Vector 的位置

Truncated Self-Attention
有時候 Sequence 會超長,造成 Attention Matrix 太大,計算量太大,甚至 Train 不起來,因此可以用 Truncated Self-Attention,只考慮某距離以內的 Vector,不考慮太遠的 Vector

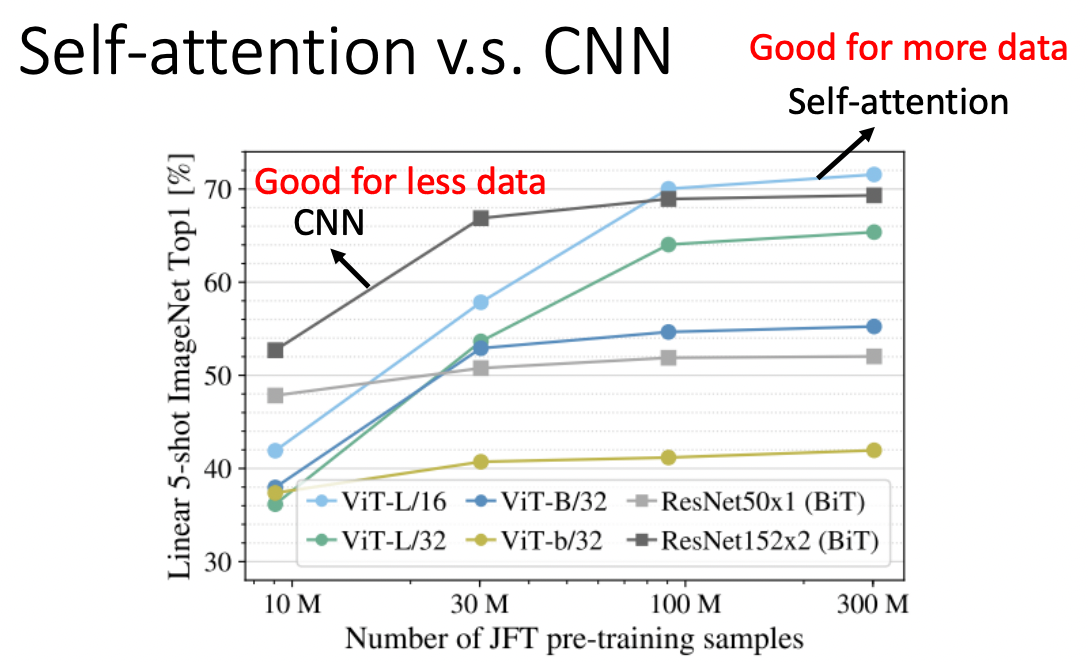
Self-Attention vs CNN
一般圖片都是用 CNN 來處理,但其實 CNN 是 Self-Attention 的一種,只是 CNN 會考慮到 Local Pattern,而 Self-Attention 會考慮到 Global Pattern
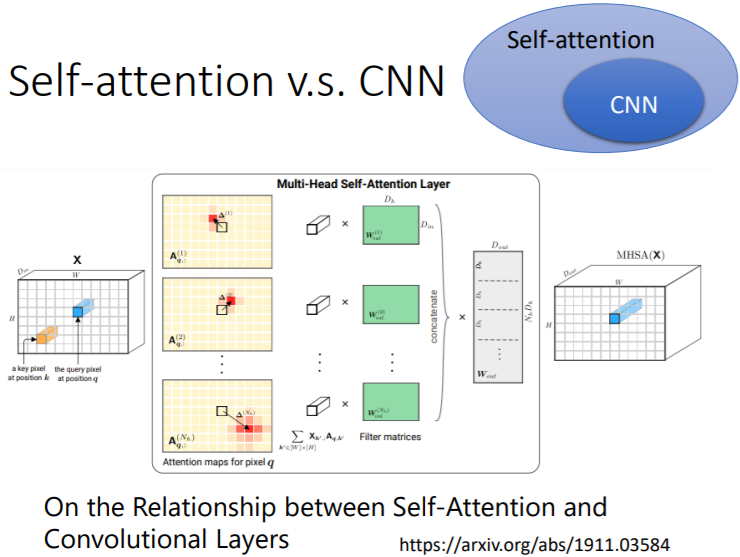
Self-Attention 就是一種更彈性的 CNN,因此在訓練資料很大的時候,Self-Attention 可能比 CNN 更好
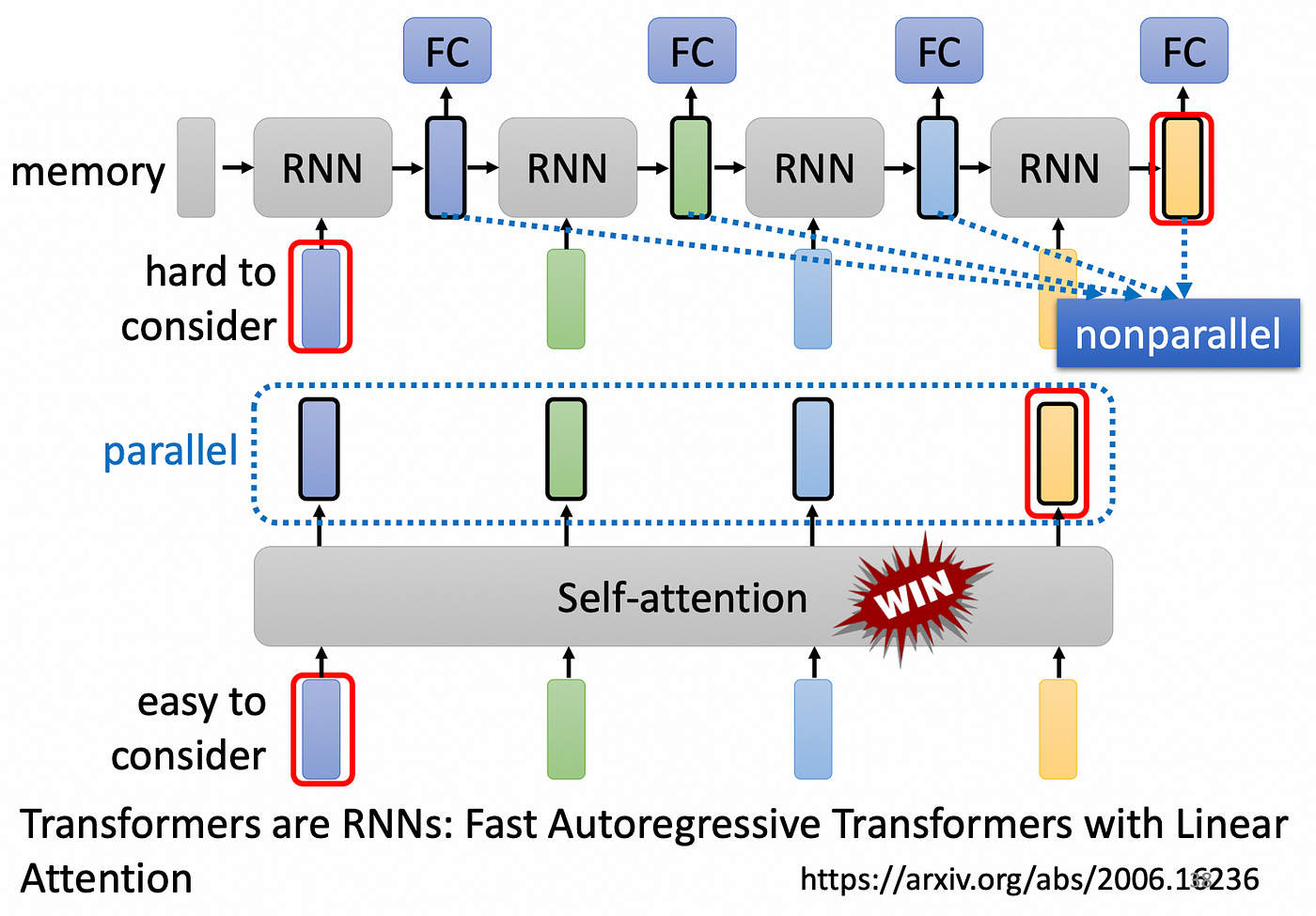
Self-Attention vs RNN
現在 RNN 幾乎被 Self-Attention 取代,因為 RNN 有兩大缺陷
Long-Term Dependency的問題,當Sequence很長時,很容易忘記越早輸入進來的資料- 只能
Sequential計算,無法平行運算
Transformer
是一個 Sequence-to-Sequence 的模型,由機器自己決定輸出的長度,常用在 Machine Translation、Speech Recognition、Speech Translation、Chatbot
大部分的 NLP 問題都可以直接看成 QA 問題,而 QA 問題都可以看成 Sequence-to-Sequence 的問題,只要把 Question 和 Context 組合在一起,丟進 Sequence-to-Sequence 的模型裡面,就可以得到答案。但是 NLP 的問題中,客製化模型的表現通常會更好。
有很多應用都可以硬用 Sequence-to-Sequence 的模型,像是 Syntacic Parsing,可以把這棵樹轉成 Sequence,直接塞進 Sequence-to-Sequence 的模型裡。其他還有 Multi-label Classification、Object Detection 等
Sequence-to-Sequence Structure
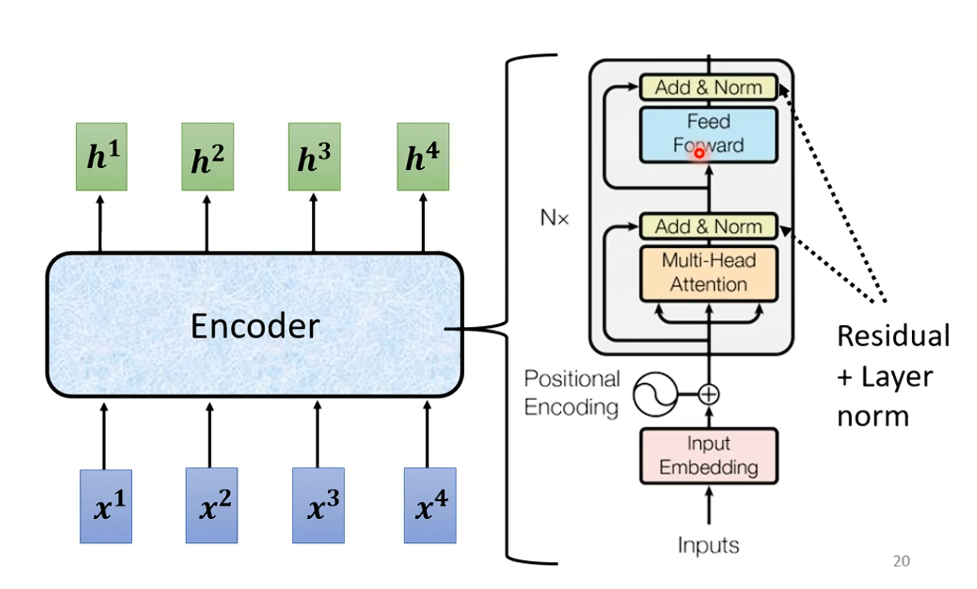
Transformer 的 Encoder 就像一位記憶力超強的老師,他把一整本書(你的輸入句子)讀完,並且整理出一本精華筆記(Encoder 的輸出)。
然後,Decoder 是一個學生,他想要用自己的話來解釋這本書的內容(生成輸出句子)。
但這位學生不會一次就把整本書背出來,而是一步一步地問老師:「接下來我要怎麼說?」
每當學生說出一個單詞,他就會回頭看看老師的筆記(Cross-Attention),確認自己沒說錯,然後再繼續下一個單詞。
所以,Encoder 負責總結資訊,Decoder 負責一步步產生句子,並透過 Cross-Attention 確保自己說的話合理。
Encoder