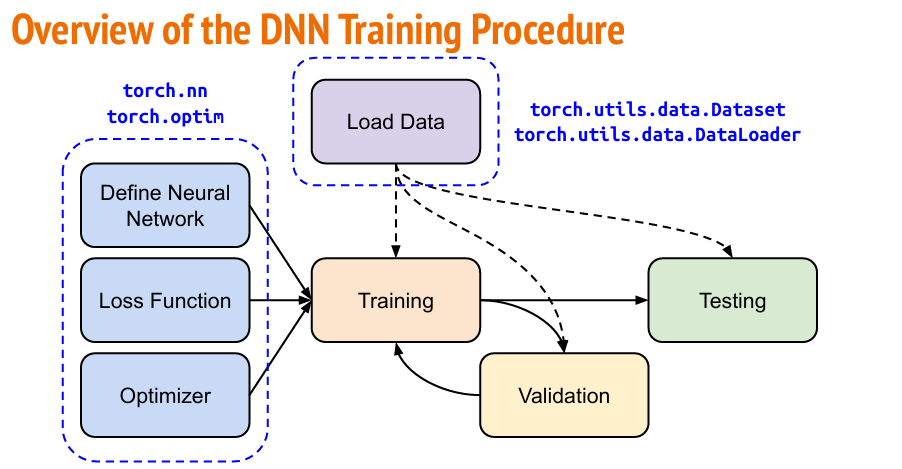
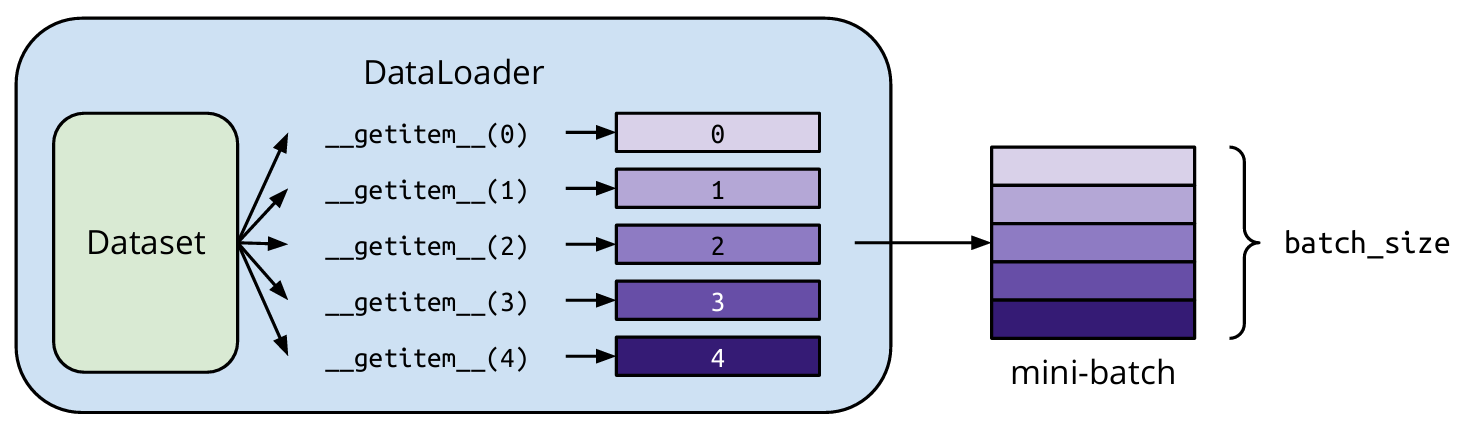
for epoch inrange(num_epochs): model.train() # Set the model to training mode for x, y in training_set: x, y = x.to('cuda'), y.to('cuda') # Move the data to GPU optimizer.zero_grad() # Clear the gradient y_pred = model(x) # Forward pass loss = criterion(y_pred, y) # Compute the loss loss.backward() # Compute the gradient optimizer.step() # Update the parameters
Evaluation (Validation)
1 2 3 4 5 6 7 8 9 10
model.eval() # Set the model to evaluation mode total_loss = 0 for x, y in validation_set: x, y = x.to('cuda'), y.to('cuda') with torch.no_grad(): # Disable gradient computation y_pred = model(x) loss = criterion(y_pred, y)
total_loss += loss.cpu().item() * x.size(0) # Accumulate the loss avg_loss = total_loss / len(validation_set.dataset) # Compute the average loss
Evaluation (Testing)
1 2 3 4 5 6 7
model.eval() # Set the model to evaluation mode predictions = [] for x in test_set: x = x.to('cuda') with torch.no_grad(): # Disable gradient computation y_pred = model(x) predictions.append(y_pred.cpu())
Save & Load Model
1 2 3 4
torch.save(model.state_dict(), path) # Save the model
checkpoint = torch.load(path) # Load the model model.load_state_dict(checkpoint)